
Sistemas de recomendação são fundamentais em e-commerces, mas o que são?
Com plataformas com milhares de itens, como conectar os usuários aos conteúdos certos, que terão relevância? Para responder a essa pergunta, surgem os sistemas de recomendação, uma solução para personalizar os conteúdos apresentados aos usuários.
E quando bem aproveitados, os sistemas de recomendação trazem resultados expressivos. O da Netflix, por exemplo, gera $1 bilhão de lucro por ano, sendo o mecanismo por trás de 80% dos conteúdos vistos na plataforma.
Mas não fica só por aí. E-commerces e demais formas de comércio eletrônico como marketplaces, redes sociais e buscadores como o Google também se valem do recurso. Tudo isso com o objetivo de proporcionar uma experiência de navegação única para cada usuário e ao mesmo tempo aumentar as conversões.
Leia mais: [Case] Como o Posthaus vende 3 vezes mais com o sistema de recomendação criado pela Supero
Mas como os sistemas de recomendação fazem isso? É o que você verá neste post.
O que são sistemas de recomendação?
Sistemas de recomendação são mecanismos capazes de analisar e compreender o comportamento dos usuários de uma plataforma para fazer recomendações relevantes e personalizadas de conteúdos novos.
A ideia é entregar, entre uma gama enorme de possibilidades existentes, sugestões precisas, que vão levar a um aumento na interação, conversões e, logo, satisfação na experiência do usuário.
Por isso, sistemas de recomendação cumprem funções fundamentais em plataformas como e-commerces, redes sociais ou grandes catálogos: quanto mais itens disponíveis, mais difícil reter a atenção do usuário e conectá-lo diretamente ao que ele se interessa.
Não à toa, eles têm se tornado mais e mais presentes – e necessários – na jornada de compra online.
Mas como os sistemas de recomendação funcionam? Com algoritmos, isto é, modelo de machine learning.

Algoritmos dos sistemas de recomendação
Na vida real, é comum pedir e fazer recomendações de filmes, livros, restaurantes, marcas e outras coisas para as pessoas. Já parou para pensar que critérios utilizamos para responder com as opções mais adequadas àquela pessoa em especial? De maneira quase que instantânea, pensamos nos gostos, hábitos de consumo, poder de compra e histórico, concorda?
O segredo está no dados. Analisamos intuitivamente vários dados e os combinamos entre si para chegar à síntese, que é a indicação.
Se isso é muito simples e direto no mundo real, no universo de uma plataforma digital – que coleta volumes imensos de dados sobre itens, usuários e a interação entre ambos – você precisa processar muita informação para indicar alguma coisa. Então chegamos ao conceito de algoritmo.
Algoritmo é uma sequência de operações para resolver um problema ou fazer um cálculo. No caso das recomendações, essas operações são baseadas em um treinamento em dados (machine learning) que visa descobrir padrões de comportamento – como similaridades, proximidades – encobertos neles. Desdobertos os padrões, será possível predizer possíveis comportamentos futuros e fazer sugestões.
Veja mais: Machine learning vs. deep learning: você sabe realmente a diferença?
Tipos de algoritmos dos sistemas de recomendação
Os sistemas de recomendação seguem processos definidos por algoritmos para sugerir conteúdos, mas não há apenas uma possibilidade. Diferentes critérios podem ser usados para compreender o perfil de consumo de informação do usuário. Cada um desses tipos dá origem a um tipo de filtragem.
1. Baseada em conteúdo
A abordagem baseada em conteúdo usa informações sobre os usuários e os itens. Isso dá origem a duas análises:
- Se o usuário tem tais características, usuários com características similares terão comportamentos parecidos. P. ex.: Homens jovens moradores de áreas urbanas gostam de sci-fy, logo outro perfil similar deve gostar também.
- Se o usuário interage com itens com tais características, também deve interagir com itens com características similares. Por exemplo: usuários que gostam de Mad Max provavelmente também gostarão de Blade Runner.
A lógica é a da semelhança. Veja que, nesse sistema, embora o usuário não precise gerar dados explicitamente, é necessário ter muitos dados sobre o usuário e sobre os itens. Por isso, esse tipo de sistema de recomendação é ideal em plataformas em que os usuários precisem realizar algum tipo de cadastro de perfil.
A vantagem do cadastro prévio é que ele evita o problema do cold start, ou seja, da recomendação aos usuários novos, que ainda não interagiram ou converteram em nenhum item.
No entanto, essa abordagem pode criar bolhas de conteúdo. Ao selecionar apenas opções por semelhança, o sistema de recomendação por conteúdo não apresenta diversidade, o que limita as chances de ampliar o padrão de consumo.
Outra limitação dos sistemas de recomendação baseados em conteúdo é a definição de semelhança, que pode gerar resultados que fazem pouco sentido.
2. Colaborativa
Na filtragem colaborativa serão analisadas as interações passadas dos usuários com os produtos e, com base em dados explícitos como avaliações (por isso colaborativa, porque conta com o usuário) ou implícitos, detectadas similaridades no comportamento dos vários usuários ou em avaliações de produtos.
Isso pode ser representado de maneira bem simples por meio de uma matriz como a abaixo:
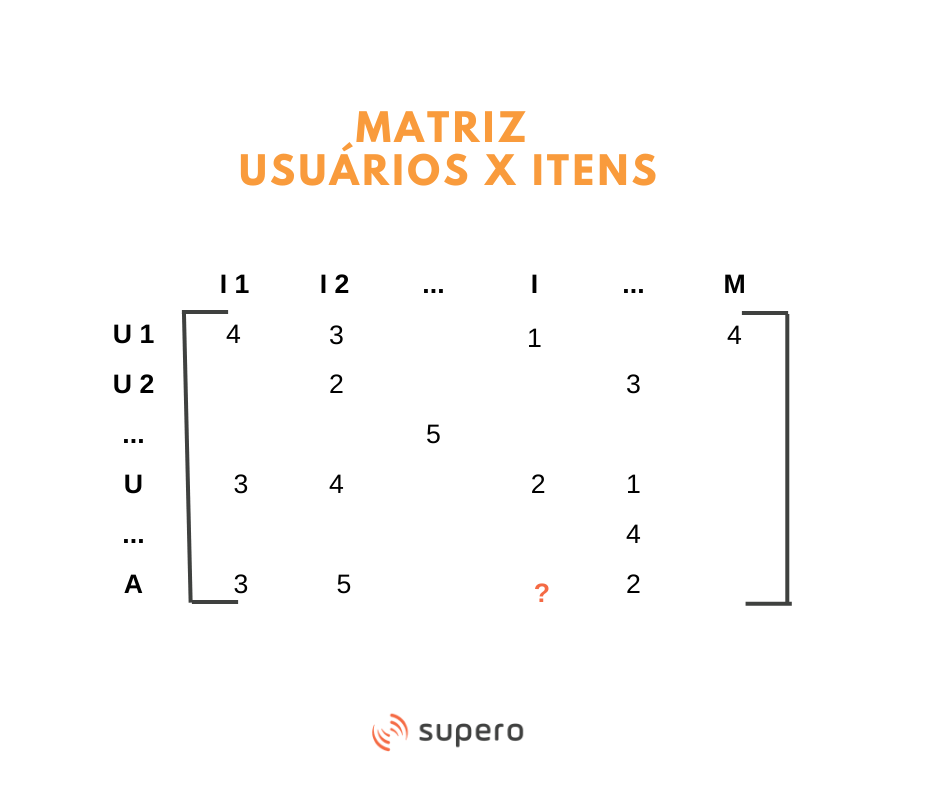
Nessa matriz, cada célula corresponde à avaliação dada ao Item pelo Usuário. Perceba que nem todas as células estão preenchidas, já que nem todo usuário avalia todos os itens. A tarefa do algoritmo por fatoração matricial é predizer que avaliação um usuário daria a um item não avaliado, para entender se faz sentido apresentá-lo a ele.
Isso dá origem a recomendações por proximidade ou por modelos.
Por exemplo, na predição calculada por proximidade, você atribuirá um peso a todos os usuários quanto à similaridade com o usuário ativo, selecionará os usuários que têm mais similaridade com ele e calcular uma predição a partir da combinação das avaliações dos usuários selecionados. Já na predição baseada em item, não são os usuários que são combinados por similaridade, mas os itens.
Isso significa, diferente da abordagem baseada em conteúdo, que você não precisa saber nada nem sobre os itens nem sobre os usuários.
No entanto, para as recomendações serem cada vez mais precisas, os usuários precisam interagir cada vez mais. Então, temos dois problemas de cold start:
- Itens novos ou com poucas interações não são recomendados;
- Novos usuários – sem histórico de interação – não recebem boas recomendações.
4. Algoritmos não personalizados
Os algoritmos não personalizados são usados sobretudo para o cold start.
O cold start é mais bem definido como um problema inerente aos sistemas de recomendação. Como vimos, ele surge quando novos usuários e itens são adicionados ao sistema. É difícil de resolver porque, enquanto você não tem dados nem interações implícitas e explícitas do usuário, não é possível encontrar nem conteúdos nem perfis semelhantes.
Por isso, para esses usuários, as recomendações são mais gerais, baseadas nos principais conteúdos acessados, em geolocalização, em preços, lançamentos etc.
Embora essa recomendação não seja personalizada, a ideia por trás disso é incentivá-los a navegar e a começar a desenhar seu perfil padrão na plataforma.
4. Híbrida
Os sistema de recomendação com filtros híbridos combinam as abordagens por conteúdo e colaborativa.
A maneira mais simples de combiná-las é produzindo rankings separados de recomendações e combinando-os para produzir uma lista final.
Mas há também abordagens que tentam combinar ambas em um único framework.
Data science: como se preparar para usar sistemas de recomendação
Como você já deve ter observado, cada tipo de filtragem espera os dados de certa forma – perfil do cliente, avaliações – para trabalhar bem.
Por isso, na parte de data science, antes de o algoritmo funcionar, o trabalho é tratar os dados estatisticamente para entender se temos dados válidos para levar ou não ao filtro.
Leia também: [Entrevista] Data science: o que você precisa saber para trabalhar com dados
Por exemplo: se a plataforma tem informações claras sobre os clientes, vale a pena usar o algoritmo baseado em conteúdo. Agora, se ela não tem informação nenhuma sobre os clientes ou se essas informações forem muito dispersas, torna-se irrelevante um algoritmo de conteúdo.
De acordo com o cientista de dados Normélio Schneider Junior:
[Os tipos de filtragem] são aceleradores, algoritmos prontos para correlacionar os dados dos usuários ativados. Mas esses dados precisam passar antes por um processo de data science para a recomendação funcionar. Nela, vamos escolher a melhor forma de tratá-los.
É possível avaliar a qualidade de um sistema de recomendações?
Sim. A qualidade do sistema de recomendação pode – e deve – ser avaliada por meio de experimentos que vão comparar rankings de recomendações por usuário com um conjunto-teste de avaliações conhecidas.
Aliás, a qualidade é um dos maiores desafios dos sistemas de recomendação. Como vimos, eles dependem de dados que podem ter alta variância e dispersão ou baixa qualidade.
Leia mais: Qualidade dos dados em projetos de IA
Além disso, ao escalar o sistema de recomendação, novos desafios podem surgir, exigindo novas soluções como clusterização.
Por isso, os frameworks escolhidos para o sistema de recomendação de uma plataforma são também personalizados. Como complementa Normélio Schneider:
Não existe uma receita de bolo, em que você simplesmente pega um sistema pronto e entrega para todo mundo.
Sistemas de recomendação: a solução é personalizada
Como vimos, os sistemas de recomendação visam entregar aos usuários de uma plataforma o que é relevante para eles.
Agora, por mais que já contemos com vários algoritmos e frameworks para implementá-los, nada acontece sem um trabalho de data science prévio, que vai tanto tratar os seus dados para passarem pelos algoritmos quanto definir qual combinação de algoritmos é a mais adequada ao seu negócio.
Nós podemos ajudar você a construir o time de cientistas de dados ideal para eesse projeto. Para saber mais, fale com nossos consultores.






